In this article, I aim to delve into the capabilities of the 🦜️🔗 LangChain framework and highlight its profound impact not only on swiftly constructing generative AI workflows but also on effortlessly extending or modifying these workflows with minimal exertion.
By delving deeper into the subject matter, you will gain a comprehensive understanding of why an abstraction like the LangChain library holds immense power in accommodating changes that may arise from evolving requirements, models, runtime environments, or building blocks within your software architecture.
To save time setting up a basic flow in LangChain, I have chosen the privateGPT project as my starting point. It is a nice minimalistic retrieval QA workflow with just two Python files. With privateGPT, you can ask questions to your local documents without an internet connection, using the power of LLM. It is 100% private, and no data leaves your computer at any point. The workflow in privateGPT is built with LangChain framework and can load all models compatible with LlamaCpp and GPT4All.
In our sample scenario, I want to use the powerful Falcon 7B model to summarize the content found in our embeddings when we ask questions. As privateGPT crashes when we try to load the Falcon model, let’s try to fix it with the power of LangChain.
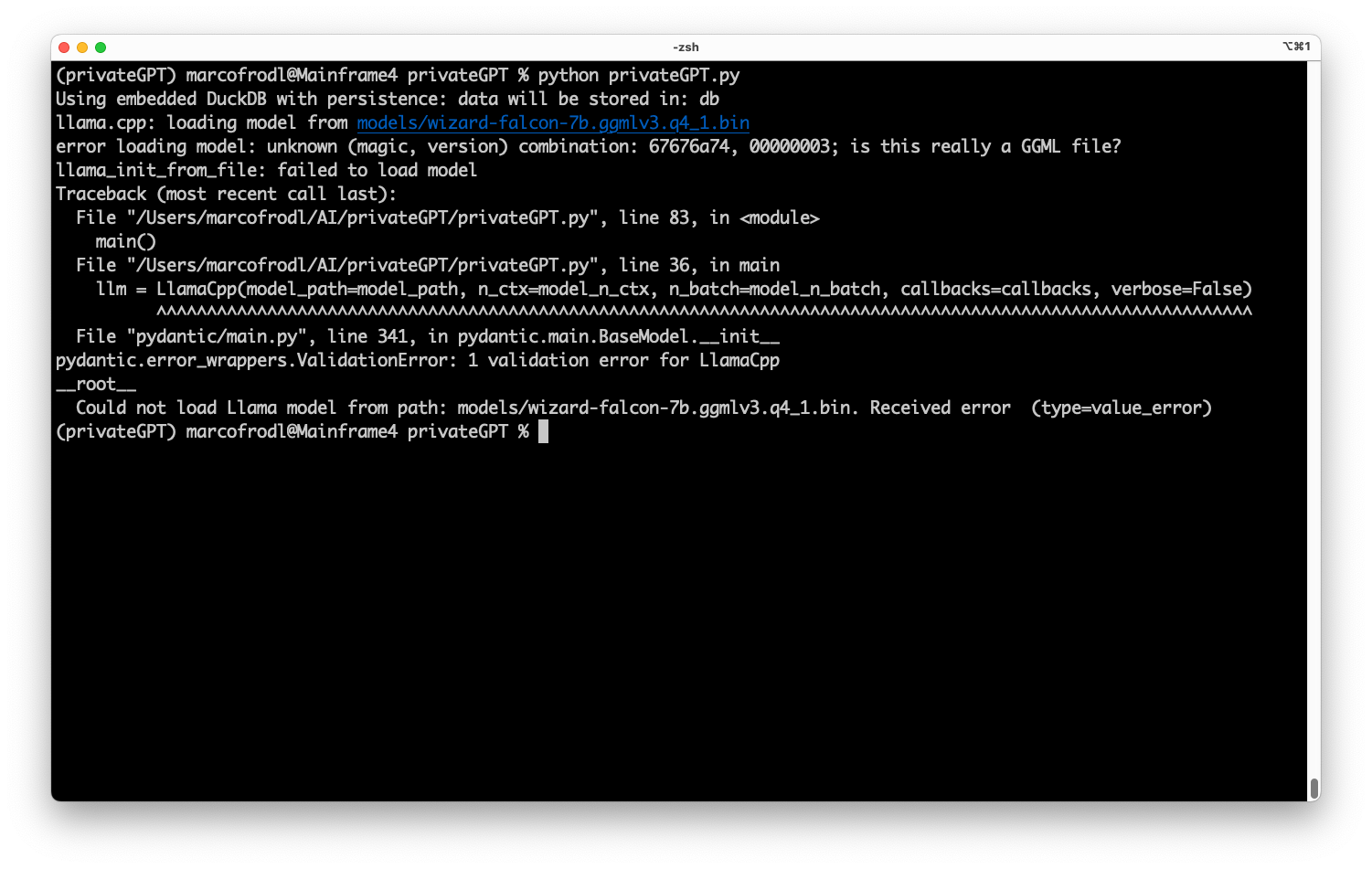
Disclaimer: It is essential to recognize that alternative solutions may exist to resolve the aforementioned issue at hand. Nonetheless, this article’s primary focus remains on unveiling the boundless possibilities and potential of LangChain as a transformative tool for AI workflows.
Project Setup
If you are already familiar with setting up virtual Python environments on your system, know how to clone a project, and install the necessary libraries, you can proceed to the next chapter.
Otherwise, it is recommended that you begin by creating a dedicated Python environment using tools like Conda. Without Conda, there’s a high chance of messing up your system during research work!
conda create --name privateGPT python=3.11.3 pip
Activate then new environment conda activate privateGPT and clone the privateGPT repository git clone https://github.com/imartinez/privateGPT.git.
The final step in our setup involves installing all the required dependencies listed in the requirements.txt file:
pip install -r requirements.txt
Preparing the Environment
Create a .env file and copy all lines from the example.env file, making the necessary changes. This is the moment to introduce our Falcon LLM file. I placed my Falcon model file in the subfolder models/ in the privateGPT directory.
PERSIST_DIRECTORY=db
MODEL_TYPE=LlamaCpp
MODEL_PATH=models/wizard-falcon-7b.ggmlv3.q4_1.bin
EMBEDDINGS_MODEL_NAME=all-MiniLM-L6-v2
MODEL_N_CTX=1000
MODEL_N_BATCH=8
TARGET_SOURCE_CHUNKS=3
You can find the Falcon 7B LLM on Huggingface. In this article, I’ll use the “Eric Hartford’s WizardLM Uncensored Falcon 7B GGML” version by The Bloke (https://huggingface.co/TheBloke/WizardLM-Uncensored-Falcon-7B-GGML). As I want to run it on my Mac with an Apple M-CPU and 16 GB RAM, I picked a quantized version that only needs 7.1 GB of RAM.
Generating the Embeddings
Run the ingest process against the state_of_the_union.txt sample document:
python ingest.py
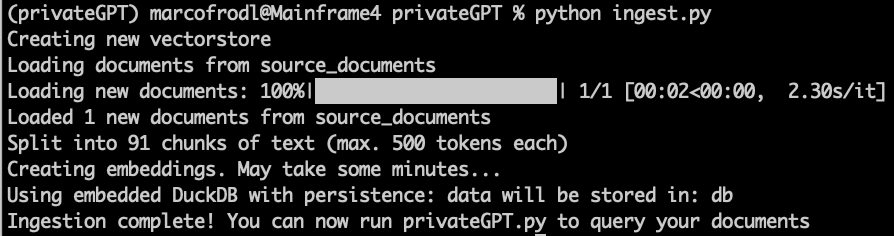
If you reference an embeddings model that you have never used before, the system will automatically initiate a download process from Huggingface to obtain the required embeddings model. Once the download is complete, the system can proceed with creating the vector database and generating the embeddings for your purposes.
The duration of this process may vary depending on the speed and stability of your internet connection. Generally, it takes a few minutes to complete the download, but this can be expedited if you have a fast and reliable internet connection. This would be the ideal time to subscribe to our Thinktecture Labs Newsletter.
Let’s Catch The Falcon with LangChain
As mentioned in the introduction of this article, the current libraries used by privateGPT cannot load the Falcon model (wizard-falcon-7b.ggmlv3.q4_1.bin), so it crashes when we start the query process. CTransformers comes to the rescue because it offers support for many more LLM types than the Llamacpp and GPT4All solutions included in the privateGPT project. Read my previous article to learn more or have a look at https://github.com/marella/ctransformers#supported-models. CTransformers is integrated into LangChain since LangChain version 0.0.181. As our base project, privateGPT uses LangChain version 0.0.197, we are covered and can move on. First, we add the CTransformer package to our Python workspace via:
pip install ctransformers
Now let’s introduce the new possibilities in our .env file where we change the MODEL_TYPE to CTransformers and add the line CTRANSFORMERS_MODEL_TYPE=falcon.
PERSIST_DIRECTORY=db
MODEL_TYPE=CTransformers
CTRANSFORMERS_MODEL_TYPE=falcon
MODEL_PATH=models/wizard-falcon-7b.ggmlv3.q4_1.bin
EMBEDDINGS_MODEL_NAME=all-MiniLM-L6-v2
MODEL_N_CTX=1000
MODEL_N_BATCH=8
TARGET_SOURCE_CHUNKS=3
As the ingest process only uses the embeddings model, we don’t need to change anything in ingest.py. But we have to tweak some aspects in privateGPT.py.
To do so, we need to tell the LangChain LLM module that we want to add support for the CTransformers library. We can do this with a small change of the import statement in the header of the privateGPT.py file.
# without CTransformers support
from langchain.llms import GPT4All, LlamaCpp
# with CTransformers support
from langchain.llms import GPT4All, LlamaCpp, CTransformers
Code language: Python (python)Now, we map our new .env parameter CTRANSFORMERS_MODEL_TYPE to a variable ctransformers_model_type = os.environ.get(‘CTRANSFORMERS_MODEL_TYPE’) so we can use it in our Python code.
# before
model_type = os.environ.get('MODEL_TYPE')
model_path = os.environ.get('MODEL_PATH')
model_n_ctx = os.environ.get('MODEL_N_CTX')
model_n_batch = int(os.environ.get('MODEL_N_BATCH',8))
target_source_chunks = int(os.environ.get('TARGET_SOURCE_CHUNKS',4))
# after
model_type = os.environ.get('MODEL_TYPE')
model_path = os.environ.get('MODEL_PATH')
model_n_ctx = os.environ.get('MODEL_N_CTX')
model_n_batch = int(os.environ.get('MODEL_N_BATCH',8))
target_source_chunks = int(os.environ.get('TARGET_SOURCE_CHUNKS',4))
ctransformers_model_type = os.environ.get('CTRANSFORMERS_MODEL_TYPE')
Code language: C# (cs)And now comes the most important part – introducing a new way in LangChain to load our model beside the existing LLaMA and GPT4All modes. As the LLM module by LangChain covers all the needed methods and features, there is nothing else required for the following code and workflow changes. Magic!
# Prepare the LLM - block before
match model_type:
case "LlamaCpp":
llm = LlamaCpp(model_path=model_path, n_ctx=model_n_ctx, n_batch=model_n_batch, callbacks=callbacks, verbose=False)
case "GPT4All":
llm = GPT4All(model=model_path, n_ctx=model_n_ctx, backend='gptj', n_batch=model_n_batch, callbacks=callbacks, verbose=False)
case _default:
# raise exception if model_type is not supported
raise Exception(f"Model type {model_type} is not supported. Please choose one of the following: LlamaCpp, GPT4All")
# Prepare the LLM - block after
match model_type:
case "LlamaCpp":
llm = LlamaCpp(model_path=model_path, n_ctx=model_n_ctx, n_batch=model_n_batch, callbacks=callbacks, verbose=False)
case "GPT4All":
llm = GPT4All(model=model_path, n_ctx=model_n_ctx, backend='gptj', n_batch=model_n_batch, callbacks=callbacks, verbose=False)
case "CTransformers":
llm = CTransformers(model=model_path, model_type=ctransformers_model_type)
case _default:
# raise exception if model_type is not supported
raise Exception(f"Model type {model_type} is not supported. Please choose one of the following: LlamaCpp, GPT4All")
Code language: Python (python)Ok, let’s run
python privateGPT.py
again.
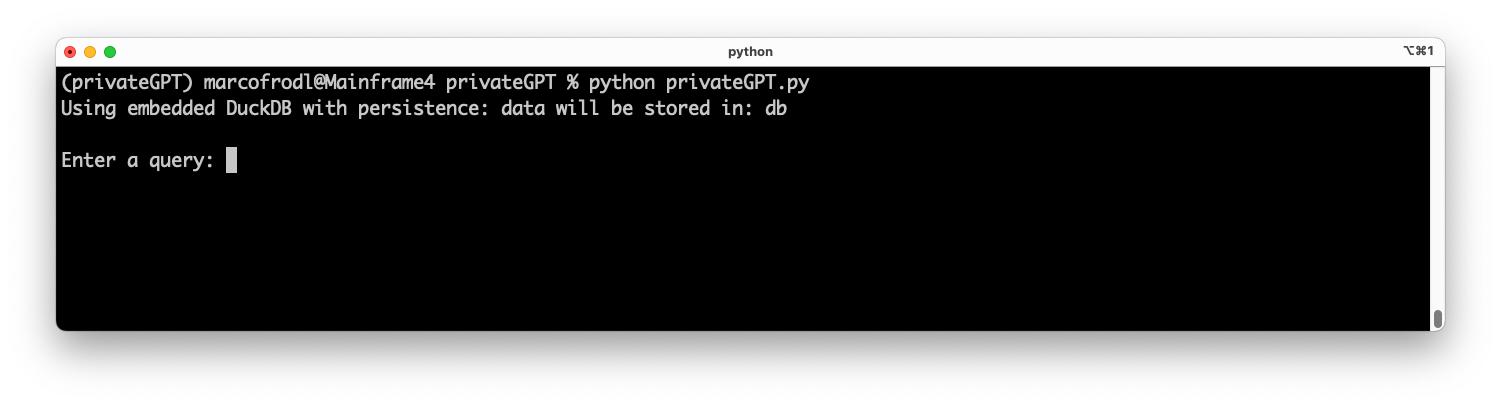
Awesome! Our privateGPT is now able to use the power of the Falcon 7B model. To do so, we only had to change one import line and add two lines for loading the model. Everything else is handled by LangChain. Let’s run a query against the state_of_the_union.txt sample document:
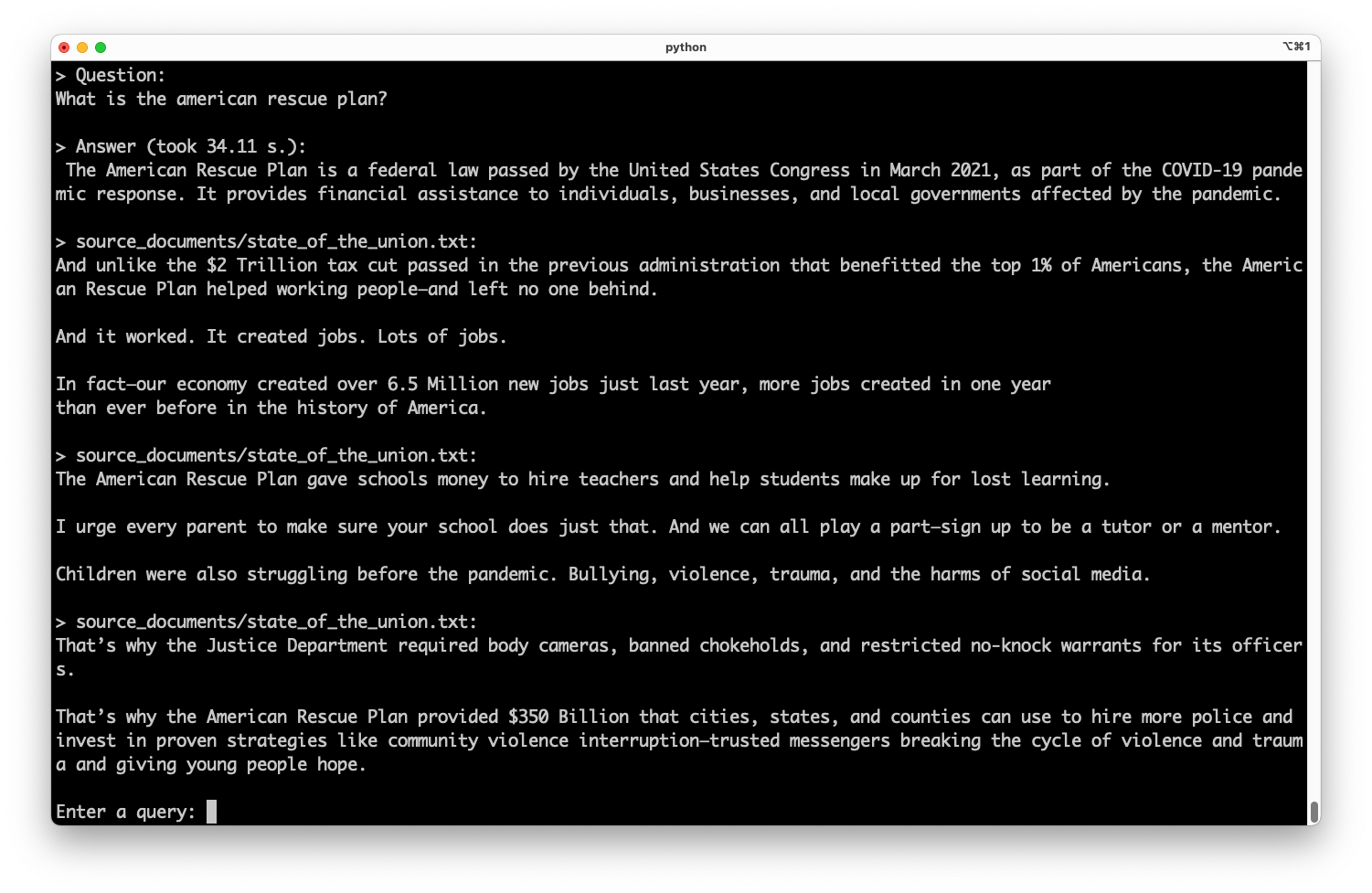
The answer appears excellent. It’s evident how the Falcon model sourced the necessary input from the embedding results and condensed it into one suitable response.
Going a step further
What about other settings from the .env file, such as MODEL_N_CTX and MODEL_N_BATCH, which can tune the parameters and output of the model?
We can incorporate them into a config object and pass it to CTransformers via LangChain. The GitHub page for CTransformers provides a table containing all possible config parameters.
| Parameter | Type | Description | Default |
|---|---|---|---|
top_k | int | The top-k value to use for sampling. | 40 |
top_p | float | The top-p value to use for sampling. | 0.95 |
temperature | float | The temperature to use for sampling. | 0.8 |
repetition_penalty | float | The repetition penalty to use for sampling. | 1.1 |
last_n_tokens | int | The number of last tokens to use for repetition penalty. | 64 |
seed | int | The seed value to use for sampling tokens. | -1 |
max_new_tokens | int | The maximum number of new tokens to generate. | 256 |
stop | List[str] | A list of sequences to stop generation when encountered. | None |
stream | bool | Whether to stream the generated text. | False |
reset | bool | Whether to reset the model state before generating text. | True |
batch_size | int | The batch size to use for evaluating tokens. | 8 |
threads | int | The number of threads to use for evaluating tokens. | -1 |
context_length | int | The maximum context length to use. | -1 |
gpu_layers | int | The number of layers to run on GPU. | 0 |
This helps us to map MODEL_N_CTX and MODEL_N_BATCH.
For fun, let’s also set the max_new_tokens limit from default 256 to 2000 so that the model can generate more output. We define the config dictionary for all of that in a line below ctransformers_model_type definition.
# before
ctransformers_model_type = os.environ.get('CTRANSFORMERS_MODEL_TYPE')
#after
ctransformers_model_type = os.environ.get('CTRANSFORMERS_MODEL_TYPE')
ctransformers_config = {'max_new_tokens': 2000, 'batch_size': model_n_batch, 'context_length': int(model_n_ctx)}
Code language: C# (cs)Then we pass it to the model loader as an additional parameter.
# before
case "CTransformers":
llm = CTransformers(model=model_path, model_type=ctransformers_model_type)
# after
case "CTransformers":
llm = CTransformers(model=model_path, model_type=ctransformers_model_type, config=ctransformers_config)
Code language: C# (cs)We run the query again, and everything should still work while we now have full control over every aspect of our Falcon model.
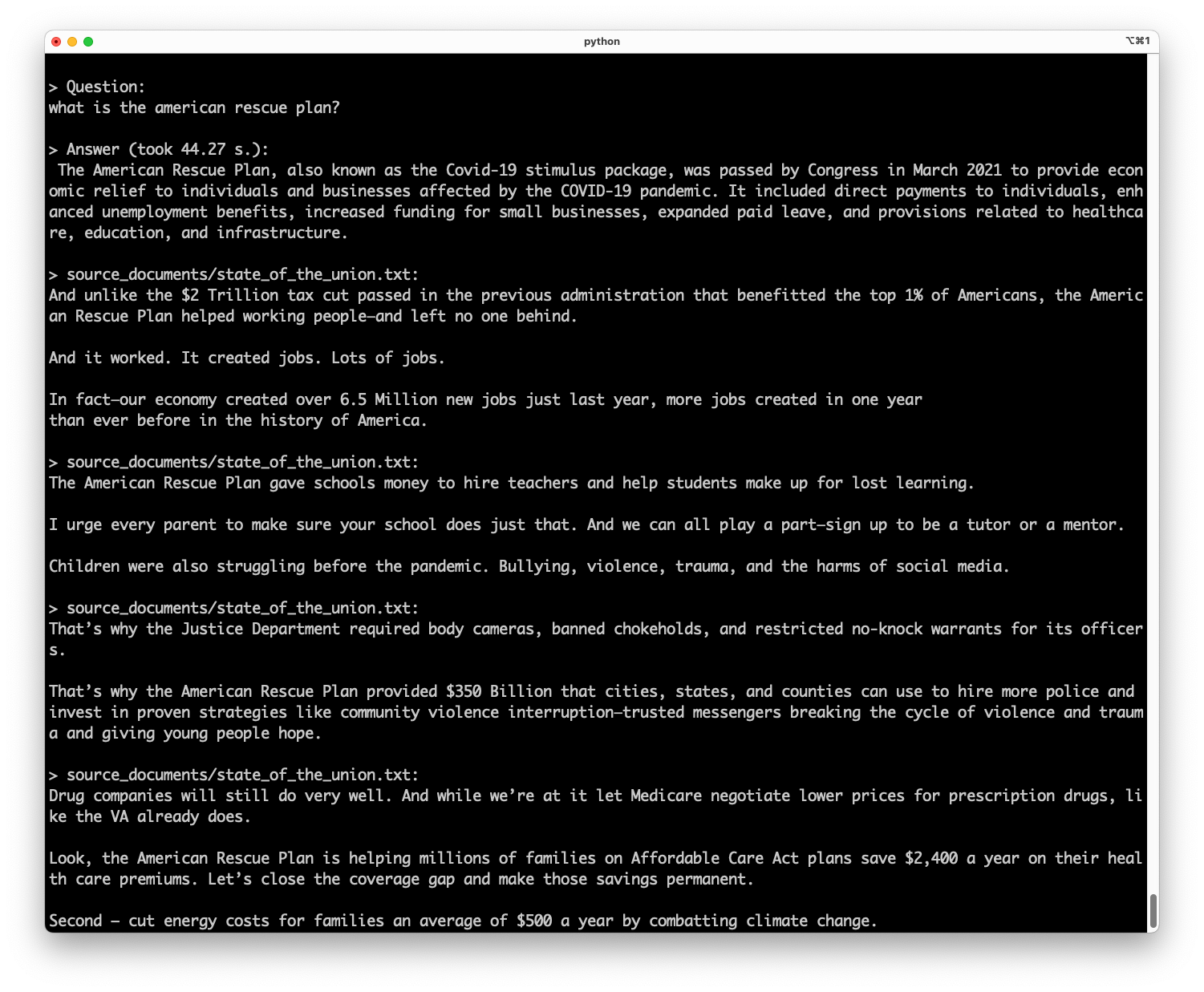
Conclusion
The flexibility of the LangChain framework makes it a powerful tool in the world of AI workflows. Its potential is vividly displayed through its seamless integration with different models, ease of updating or extending software architecture, and accommodation for evolving requirements.
By implementing the Falcon 7B large language model in the privateGPT project using LangChain, we have demonstrated how elegantly and efficiently a new LLM can be incorporated into existing systems. Despite initial issues encountered due to compatibility, adopting LangChain not only resolved these issues but also offered enhanced capabilities and expanded library support.
Through this article, I hope you’ve gleaned valuable insights about how LangChain helps to future-proof your AI projects. Its ability to accommodate new models like Falcon 7B while utilizing minimal code adjustments significantly reduces development time and increases efficiency for your generative AI projects.
Beyond that, its inherent capacity to facilitate control over every aspect of our model provides unprecedented customization options for developers. As shown in this tutorial, the power of frameworks like LangChain lies not only in their immediate functional offerings but also in their potential to adapt and evolve in harmony with technological advancements.
With such robust tools at our disposal, we’re better equipped than ever before to harness the full potential of AI technologies, driving innovation forward while navigating an ever-evolving digital landscape.