Text-to-Speech – Why It’s Important For The Big Picture
At the OpenAI DevDay on November 6th, there were so many product updates announced that it was easy to lose track. With 128k more context size for GPT-4, APIs for DALL-E 3, Text-to-Speech, and GPT-4 Vision, JSON mode, optimized pricing, improved rate limits, and much more, it was initially difficult to place all announcements into an overarching scheme.
However, in my view, there is a sensible plan or a common thread behind all of it. The new API for OpenAI Text-to-Speech (TTS) is a prime example of this. It shows how cleverly OpenAI is creating a comprehensive ecosystem for solutions build with Generative AI.
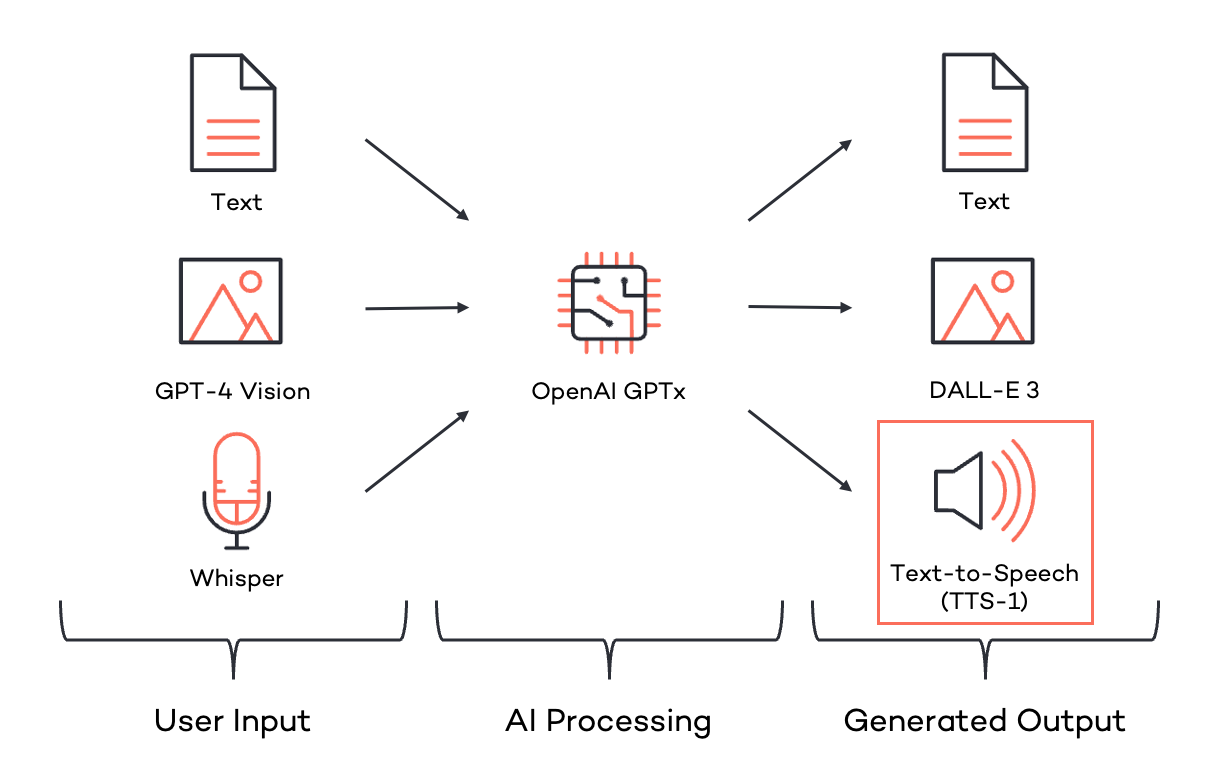
First, let’s look at the input channels for feeding information into Generative AI. ChatGPT started with text inputs (in various formats) and quickly became more accessible and flexible through Speech-to-Text via Whisper. By the end of September 2023, OpenAI GPT-4 could also “see” – GPT-4 Vision made its way into ChatGPT (although it was not available via API at that point).
Just a few weeks later, OpenAI addressed the output channels for the results generated by GPT. In addition to written output, the possibility of image-based output was introduced with DALL-E 3. The only missing piece was the conversion of textual results into speech – Text-to-Speech. Looking at the diagram, it’s easy to see that now both input and output sides cover all types of information representation. OpenAI can now respond in a manner consistent with the input vector or transform it quickly. The picture is now complete.
What can OpenAI Text-to-Speech API do?
The API documentation for TTS is very structured and easy to understand.
TTS Output Quality
There are two different levels of output quality. For rapid outputs with low latency under normal quality requirements, the level “tts-1” serves the purpose. If excellent quality of the output is important but generation time is not critical, then “tts-1-hd” would be the right choice.
Different Voices of TTS
With the voice variants Alloy, Echo, Fable, Onyx, Nova, and Shimmer, one can choose from 6 different voices. The first four voices are masculine, while Nova and Shimmer enable feminine voice output. Alloy is interesting because this voice could also pass for feminine, making it a neutral option.
Output Formats of TTS
For output, there are lossy, compressed formats such as MP3, Opus and AAC, and FLAC as lossless format one can choose from. This saves the otherwise often necessary conversion step of other solutions that generate a bothersome extra effort by only offering WAV as a format.
Hidden Feature “Talk Speed”
The TTS documentation does not initially hint that the speaking speed of the voices can be varied. Only in the API reference one can find the option to control the output speed between a factor of 0.25x to 4x the speed – perfect for quickly presenting information from medication leaflets.
The Best Voices of OpenAI Text-to-Speech for German Output
The API documentation’s note, that the output currently works best with English, should be taken seriously. In tests with German content, most voices had a noticeable English accent. Useful results with German output are most likely to be achieved with the voices Fable and Nova.
Code sample for using the OpenAI Text-to-Speech API
The code to call the OpenAI TTS API is quite simple and straightforward. Make sure you have installed the necessary dependencies openai, tiktoken and cohere. Now you can call the API with your text input:
from pathlib import Path
from openai import OpenAI
client = OpenAI()
speech_file_path = "/content/output-fable.mp3"
response = client.audio.speech.create(
model="tts-1",
voice="fable",
speed=1,
input="Wir sind __Thinktecture__! Wir helfen Softwareentwicklern und Architekten, das meiste aus A.I., Angular, Blazor und Dot NET herauszuholen."
)
response.stream_to_file(speech_file_path)
Code language: Python (python)You can also use my shared Colab notebook as a head start.
Trying Out OpenAI Text-to-Speech Without Using the API
For those who would like to try out OpenAI TTS without the need to integrate the API, there’s a solution. For this article, I have made the TTS API accessible with a Gradio UI on a Huggingface Space. After entering your own OpenAI API key, all previously mentioned parameters can be set and tried out. The result of the speech synthesis can be directly listened to in the browser and downloaded if necessary.
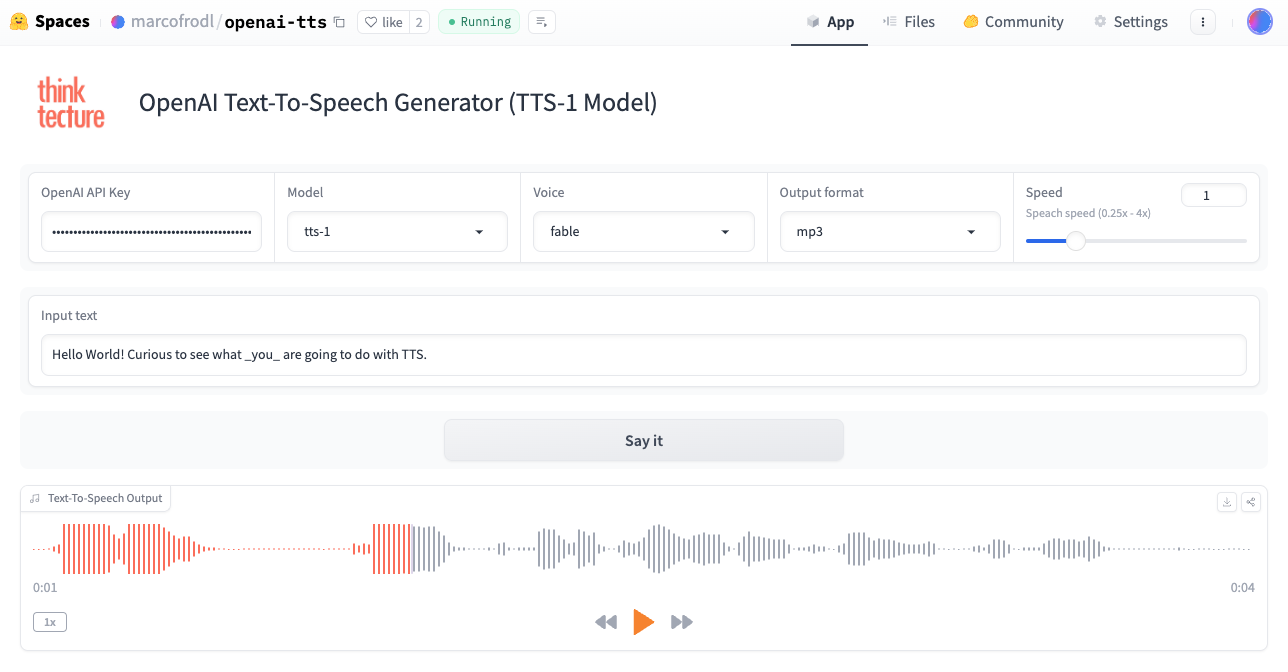
One More Thing – Influencing the Emphasis of TTS
Officially, there is no way to influence the emphasis of the voice output. However, in my tests, I have found two ways that work well.
Speaking abbreviations correctly: For abbreviations like “AI,” it can be helpful depending on the chosen voice to work with periods. The voices Fable and Nova pronounce “A.I.” reliably better than “AI”. The other voices with their English accent apparently do not need this aid.
Setting emphasis: the right emphasis can _significantly_ improve the meaning and mood of a voice output. Although it is officially not possible, this can be done using underscores “_” in the text. The word “_significantly_” would thus be emphasised more strongly, and the emphasis can be increased with several underscores, making both “_slightly_” and “__strongly__” emphasised a reality.
Conclusion
For me, OpenAI TTS is the missing piece of the puzzle and rounds off the picture for outputting information generated with Generative AI well. The API is simple but also has a few undocumented tricks up its sleeve. For German content, the voices Fable and Nova are currently the best. For initial quick tests, the demo project on Huggingface, including the source code, is a good start.